概述Hadoop archives 是特殊的档案格式。一个 Hadoop archive 对应一个文件系统目录。 Hadoop archive 的扩展名是 *.har。Hadoop archive 包含元数据(形式是 _index 和 _masterindx)和数据(part-*)文件。_index 文件包含了档案中文件的文件名和位置信息。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如何 w397090770 6年前 (2018-09-17) 2120℃ 0评论1喜欢
2019年10月22日上午 Databricks 宣布,已经完成了由安德森-霍洛维茨基金(Andreessen Horowitz)牵头的4亿美元F轮融资,参与融资的有微软(Microsoft)、Alkeon Capital Management、贝莱德(BlackRock)、Coatue Management、Dragoneer Investment Group、Geodesic、Green Bay Ventures、New Enterprise Associates、T. Rowe Price和Tiger Global Management。经过这次融资,Databricks 的估值高达62亿美 w397090770 5年前 (2019-10-22) 1119℃ 0评论0喜欢
题目:一个数组里,除了三个数是唯一出现的,其余的都出现偶数个,找出这三个数中的任一个。比如数组元素为【1, 2,4,5,6,4,2】,只有1,5,6这三个数字是唯一出现的,我们只需要输出1,5,6中的一个就行。下面是我的思路:这个数组元素个数一定为奇数,而且那要求的三个数一定不可能每一bit位都相同,所以我们可以找到其中一个b w397090770 12年前 (2013-03-31) 4066℃ 1评论4喜欢
为了提高本博客的用户体验,我于去年七月写了一份代码,将博客与微信公共帐号关联起来(可以参见本博客),用户可以在里面输入相关的关键字(比如new、rand、hot),但是那时候关键字有限制,只能对文章的分类进行搜索。不过,今天我修改了自动回复功能相关代码,目前支持对任意的关键字进行全文搜索,其结果相关与调用 w397090770 9年前 (2015-11-07) 2109℃ 0评论8喜欢
最近写了一个Spark程序用来读取Hbase中的数据,我的Spark版本是1.6.1,Hbase版本是0.96.2-hadoop2,当程序写完之后,使用下面命令提交作业:[code lang="java"][iteblog@www.iteblog.com $] bin/spark-submit --master yarn-cluster --executor-memory 4g --num-executors 5 --queue iteblog --executor-cores 2 --class com.iteblog.hbase.HBaseRead --jars spark-hbase-connector_2.10-1.0.3.jar,hbase-common-0.9 w397090770 8年前 (2016-11-03) 3627℃ 0评论7喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 9年前 (2015-05-15) 4811℃ 0评论3喜欢
今天在项目中用到了Scala正则表达式,网上找了好久也没找到很全的资料,这里收集了Scala中很多常用的正则表达式使用方法。关于Scala正则表达式替换请参见:《Scala正则表达式替换》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> val regex="""([0-9]+) ([a-z]+)& w397090770 10年前 (2015-01-04) 24897℃ 0评论27喜欢
Apache Zeppelin 0.6.2发布。从上一个版本开始,Apache Zeppelin社区就在努力解决对Spark 2.0的支持以及一些Bug的修复。本次共有26位贡献者提供超过40多个补丁改进Apache Zeppelin和Bug修复。从Apache Zeppelin 0.6.1版本开始,编译的时候默认使用Scala 2.11。如果你想使用Scala 2.10来编译Apache Zeppelin,或者安装使用Scala 2.10编译的interpreter请参见官方文 w397090770 8年前 (2016-10-18) 2025℃ 0评论2喜欢
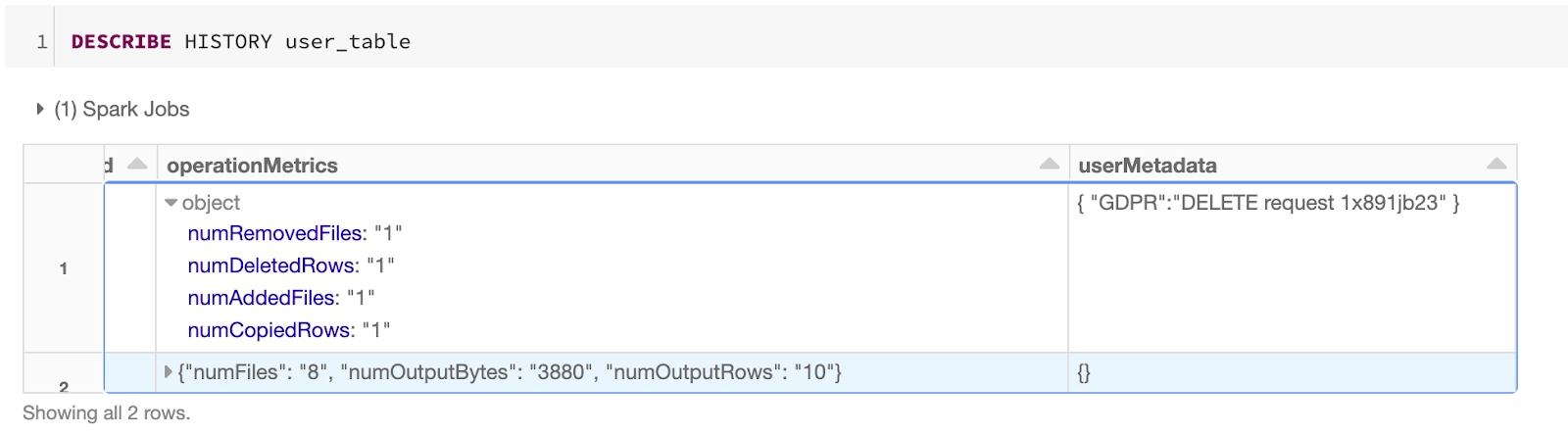
Delta Lake 0.7.0 是随着 Apache Spark 3.0 版本发布之后发布的,这个版本比较重要的特性就是支持使用 SQL 来操作 Delta 表,包括 DDL 和 DML 操作。本文将详细介绍如何使用 SQL 来操作 Delta Lake 表,关于 Delta Lake 0.7.0 版本的详细 Release Note 可以参见这里。使用 SQL 在 Hive Metastore 中创建表Delta Lake 0.7.0 支持在 Hive Metastore 中定义 Delta 表,而且这 w397090770 4年前 (2020-09-06) 1151℃ 0评论0喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列的介 w397090770 8年前 (2016-07-05) 8864℃ 0评论12喜欢
Spark 1.5.0是1.x线上的第6个发行版。这个版本共处理了来自230+contributors和80+机构的1400+个patches。Spark 1.5的许多改变都是围绕在提升Spark的性能、可用性以及操作稳定性。Spark 1.5.0焦点在Tungsten项目,它主要是通过对低层次的组建进行优化从而提升Spark的性能。Spark 1.5版本为Streaming增加了operational特性,比如支持backpressure。另外比较重 w397090770 9年前 (2015-09-09) 2997℃ 0评论12喜欢
Apache Spark Graph Processing图书由Rindra Ramamonjison所著,全书共148页;Packt Publishing出版社于2015年09月出版。 通过本书你将学习到以下内容 (1)、Write, build and deploy Spark applications with the Scala Build Tool. (2)、Build and analyze large-scale network datasets (3)、Analyze and transform graphs using RDD and graph-specific operations (4) w397090770 8年前 (2017-02-12) 1863℃ 0评论1喜欢
一直运行的Spark Streaming程序如何关闭呢?是直接使用kill命令强制关闭吗?这种手段是可以达到关闭的目的,但是带来的后果就是可能会导致数据的丢失,因为这时候如果程序正在处理接收到的数据,但是由于接收到kill命令,那它只能停止整个程序,而那些正在处理或者还没有处理的数据可能就会被丢失。那我们咋办?这里有两 w397090770 8年前 (2017-03-01) 8857℃ 1评论11喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12458℃ 0评论34喜欢
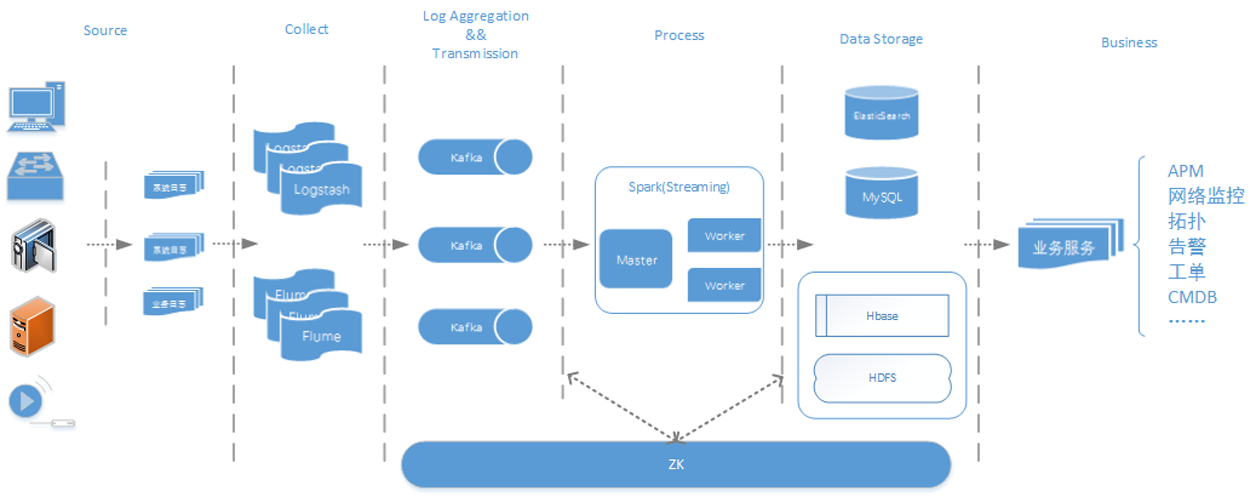
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 w397090770 8年前 (2017-01-01) 11243℃ 1评论39喜欢
Elasticsearch是一个分布式系统。当documents被创建、更新或者删除,其新版本会被复制到集群的其它节点。Elasticsearch既是异步的(asynchronous )也是同步的(concurrent),其含义是复制请求都是并行发送的,但是到达目的地的顺序是无序的。Elasticsearch系统需要一种方法使得老版本的文档永远都无法覆盖新的版本。 每当文档被改变的 w397090770 8年前 (2016-08-11) 3685℃ 1评论2喜欢
!! expr :逻辑非。%expr1 % expr2 - 返回 expr1/expr2 的余数.例子:[code lang="sql"]> SELECT 2 % 1.8; 0.2> SELECT MOD(2, 1.8); 0.2[/code]&expr1 & expr2 - 返回 expr1 和 expr2 的按位AND的结果。例子:[code lang="sql"]> SELECT 3 & 5; 1[/code]*expr1 * expr2 - 返回 expr1*expr2.例子:[code lang="sql"]> SELECT 2 * 3; 6[/code]+ w397090770 6年前 (2018-07-13) 16562℃ 0评论2喜欢
本博客的《如何申请免费好用的HTTPS证书Let's Encrypt》和《在Nginx中使用Let's Encrypt免费证书配置HTTPS》文章分别介绍了如何申请Let's Encrypt的HTTPS证书和如何在nginx里面配置Let's Encrypt的HTTPS证书。但是Let's Encrypt HTTPS证书的有效期只有90天:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop到期之 w397090770 8年前 (2016-08-07) 1588℃ 0评论4喜欢
引言Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。SparkSQL作为大数据领域的SQL实现,自然也对Join操作做了不少优化,今天主要看一下在SparkSQL中对于Join,常见的3种实现。Spark SQL中Join常用的实现Broadc zz~~ 7年前 (2017-07-09) 8319℃ 0评论16喜欢
点击试试使用Github登录我博客。 随着使用Github的人越来越多,为自己的网站添加Github登录功能也越来越有必要了。Github开放了登录API,第三方网站可以通过调用Github的OAuth相关API读取到登录用户的基本信息,从而使得用户可以通过Github登录到我们的网站。今天来介绍一下如何使用Github的OAuth相关API登录到Wordpress。 w397090770 10年前 (2015-04-12) 11934℃ 9评论12喜欢
早上时间匆忙,我将于晚点时间详细地介绍Spark 1.4的更新,请关注本博客。 Apache Spark 1.4.0的新特性可以看这里《Apache Spark 1.4.0新特性详解》。 Apache Spark 1.4.0于美国时间的2015年6月11日正式发布。Python 3支持,R API,window functions,ORC,DataFrame的统计分析功能,更好的执行解析界面,再加上机器学习管道从alpha毕业成 w397090770 9年前 (2015-06-12) 4712℃ 0评论11喜欢
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。Protocol Buffers 是一种序列化数据结构的方法。对于通过管线(pipeline)或存储数据进行通信的程序开发上是很有用的。这个方法包含一个接口描述 w397090770 7年前 (2017-06-22) 2742℃ 0评论7喜欢
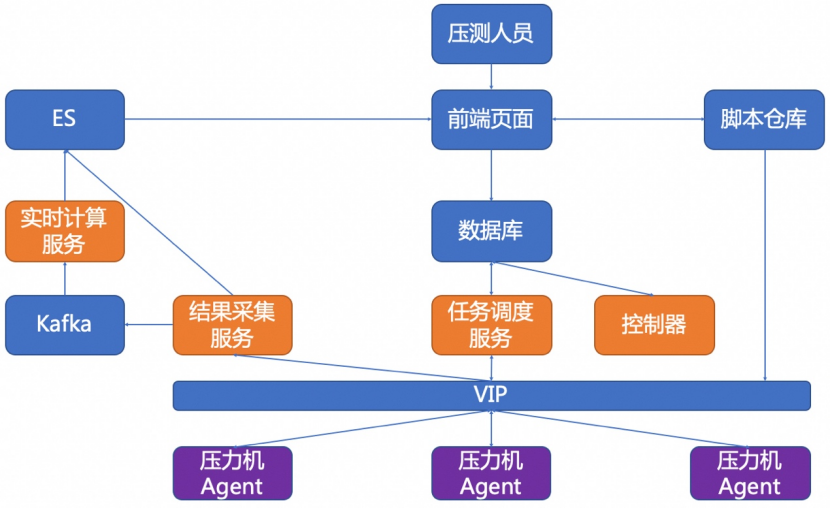
导读:压测是目前科技企业及传统企业进行系统容量评估、容量规划的最佳实践方式,本文将基于京东ForceBot平台在大促(京东618、京东双11)备战中的实践历程,给大家分享平台在压测方面的技术变革。ForceBot平台是一款分布式性能测试平台,能够为全链路压测构造千万量级的压测流量,并结合全域流量录制回放、瞬时发压、智能寻点 zz~~ 3年前 (2021-09-24) 299℃ 0评论1喜欢
Lists类主要提供了对List类的子类构造以及操作的静态方法。在Lists类中支持构造ArrayList、LinkedList以及newCopyOnWriteArrayList对象的方法。其中提供了以下构造ArrayList的函数:下面四个构造一个ArrayList对象,但是不显式的给出申请空间的大小:[code lang="JAVA"] newArrayList() newArrayList(E... elements) newArrayList(Iterable<? w397090770 11年前 (2013-09-10) 19702℃ 2评论8喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》Topic Tool $KAFKA_HOME/bin/kafka-topics.sh,该工具可用于创建、删除、修改、查看某个Topic,也可用于列出所有Topic。另外,该工具还 w397090770 9年前 (2015-06-05) 13858℃ 4评论7喜欢
Apache Hadoop 2.7.0发布。一共修复了来自社区的535个JIRAs,其中:Hadoop Common有160个;HDFS有192个;YARN有148个;MapReduce有35个。Hadoop 2.7.0是2015年第一个Hadoop release版本,不过需要注意的是 (1)、不要将Hadoop 2.7.0用于生产环境,因为一些关键Bug还在测试中,如果需要在生产环境使用,需要等Hadoop 2.7.1/2.7.2,这些版本很快会发布。 w397090770 10年前 (2015-04-24) 8837℃ 0评论14喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2015-04-25) 37445℃ 8评论55喜欢
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Big Data Analytics at a 10 zz~~ 8年前 (2016-11-21) 4677℃ 0评论6喜欢
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》当你将Kafka集群部署之后,你可能需要知道当前消息队列的增长以及消费情况,这时候你就得需要监控它。今天我这里推荐两款 Kafka 开源的监控系统:KafkaOffsetMonitor 和 Kafka Web Console。KafkaOffsetMonitor是用来实时监控K w397090770 10年前 (2014-08-07) 40755℃ 1评论18喜欢
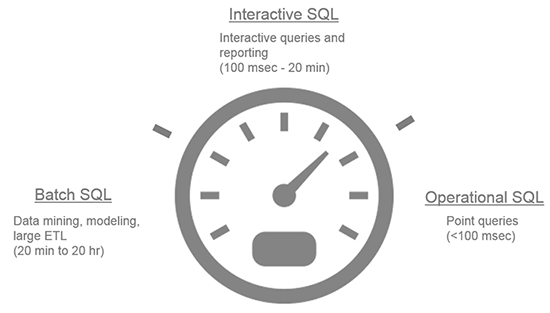
以下文章是转载自国外网站,介绍了Hadoop生态系统上面的几种SQL:Hive、Drill、Impala、Presto以及Spark\Shark等应用场景、对比以及一些结论Within the big data landscape there are multiple approaches to accessing, analyzing, and manipulating data in Hadoop. Each depends on key considerations such as latency, ANSI SQL completeness (and the ability to tolerate machine-generated SQL), developer and a w397090770 10年前 (2014-08-11) 9892℃ 0评论14喜欢






![[电子书]Apache Spark Graph Processing PDF下载](https://www.iteblog.com/pic/books/Apache_Spark_Graph_Processing_iteblog.jpg)







![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)